
무냐의 개발일지
[Coursera ML Specialization] C2 Neural Networks / Week4 (Decision tree & Ensembles) 본문
[Coursera ML Specialization] C2 Neural Networks / Week4 (Decision tree & Ensembles)
무냐코드 2024. 3. 28. 15:111. Decision Trees
- 과제에 따라 분류를 시작할거임
- 왼쪽으로 갈지, 오른쪽으로 갈지 결정을 하는 거임
- 가장 최적의 decision tree를 선택하는 게 우리의 과제임

- features : few discrete values
- labels : binary

| 결정할 중요한 요인
1. How to choose what feature to split on at each node? (to Maxize purity - 순수하게 하나의 클래스만 하위결과로 나오도록)
2. When do you stop splitting? (When node is 100% one class, When splitting a note will result in tree exceeding a max depth 너무 깊어지지 않도록, 불순도가 별로 나아지지 않을 때 When improvements in purity score are below a threshold, 한 노드에서 너무 적은 수만 남아있어서 분할하는 의미가 없을 때 When number of examples in a node is below a threshod)
2. Decision Tree learning
| Measuring purity


엔트로피 Entropy : 집합의 불순도를 측정
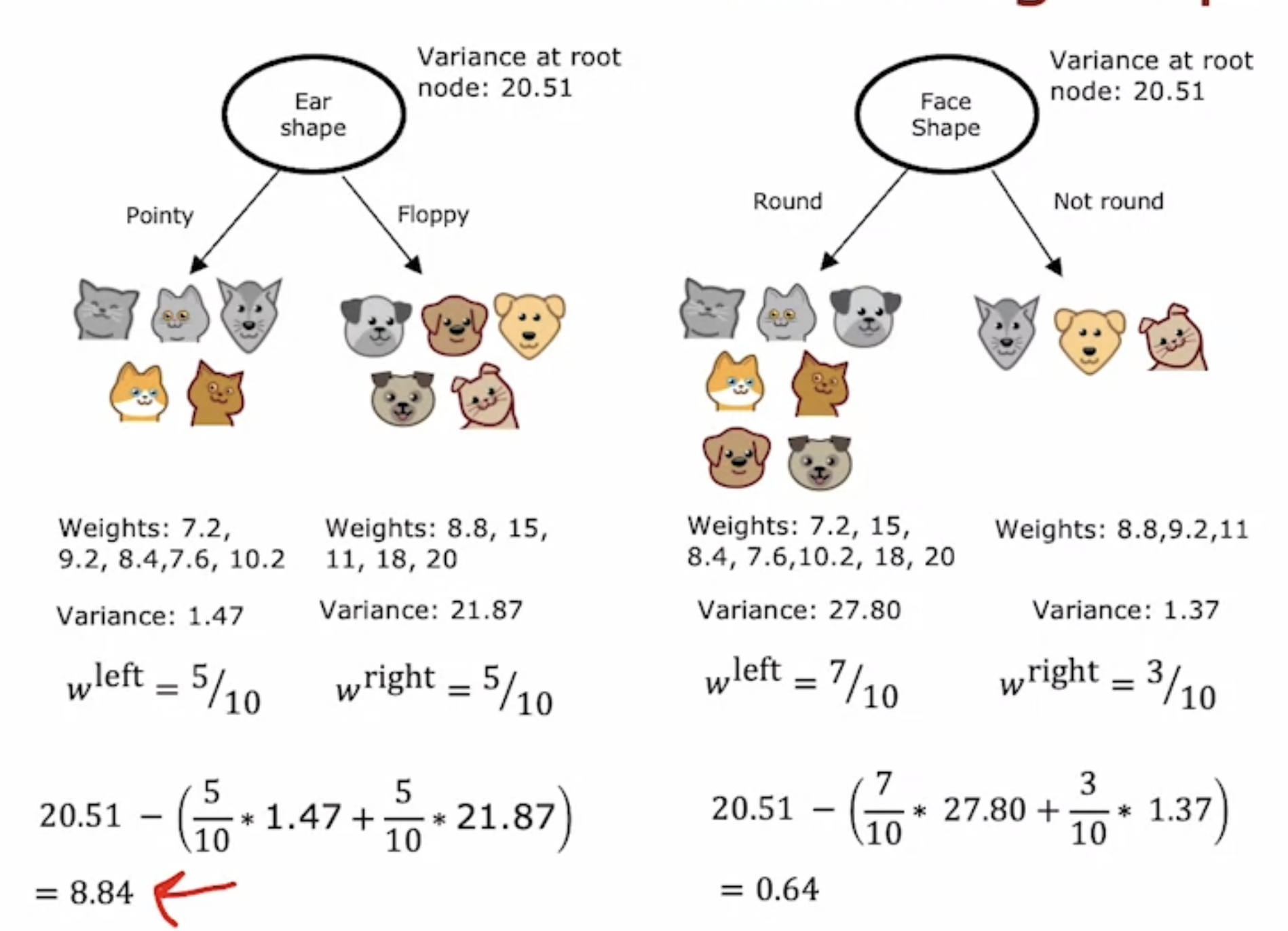
1. 어떤 feature를 선택할 것인가 (엔트로피(불순물)을 가장 줄일 수 있는 방향으로) :
- 두 가지에 모두 불순도가 적은 모델을 선택해야 좋다. 각 노드에 sample 비중에 따라 엔트로피를 적용
- 기존 root node에 분할 전 총 10개의 샘플이 있었다 -> 이 불순도에서 아래 노드의 가중평균 엔트로피를 빼면 = Information gain (엔트로피의 감소분)
| Information Gain

- Largest information gain을 주는 모델을 고른다
| One-Hot encoding for Categorical Features
3개 이상의 다른 분류가 가능해질 때 : If a categorical feature can take on k values, create k binary features (0 or 1 valued)
| Continuous Features
Decision Tree에 쓰려면 어떤 특정 숫자 기준으로 나눠야겠지
높은 Information gain을 얻을 수 있는 지점을 기준으로 split한다

- Choose the 9 mid-points between the 10 examples as possible splits, and find the split that gives the highest information gain.
| Predicting numbers (Regression)
target이 binary가 아니라 연속된 값이면? (ex. 몸무게 예측) Decision tree를 어떻게 사용할 수 있을까?
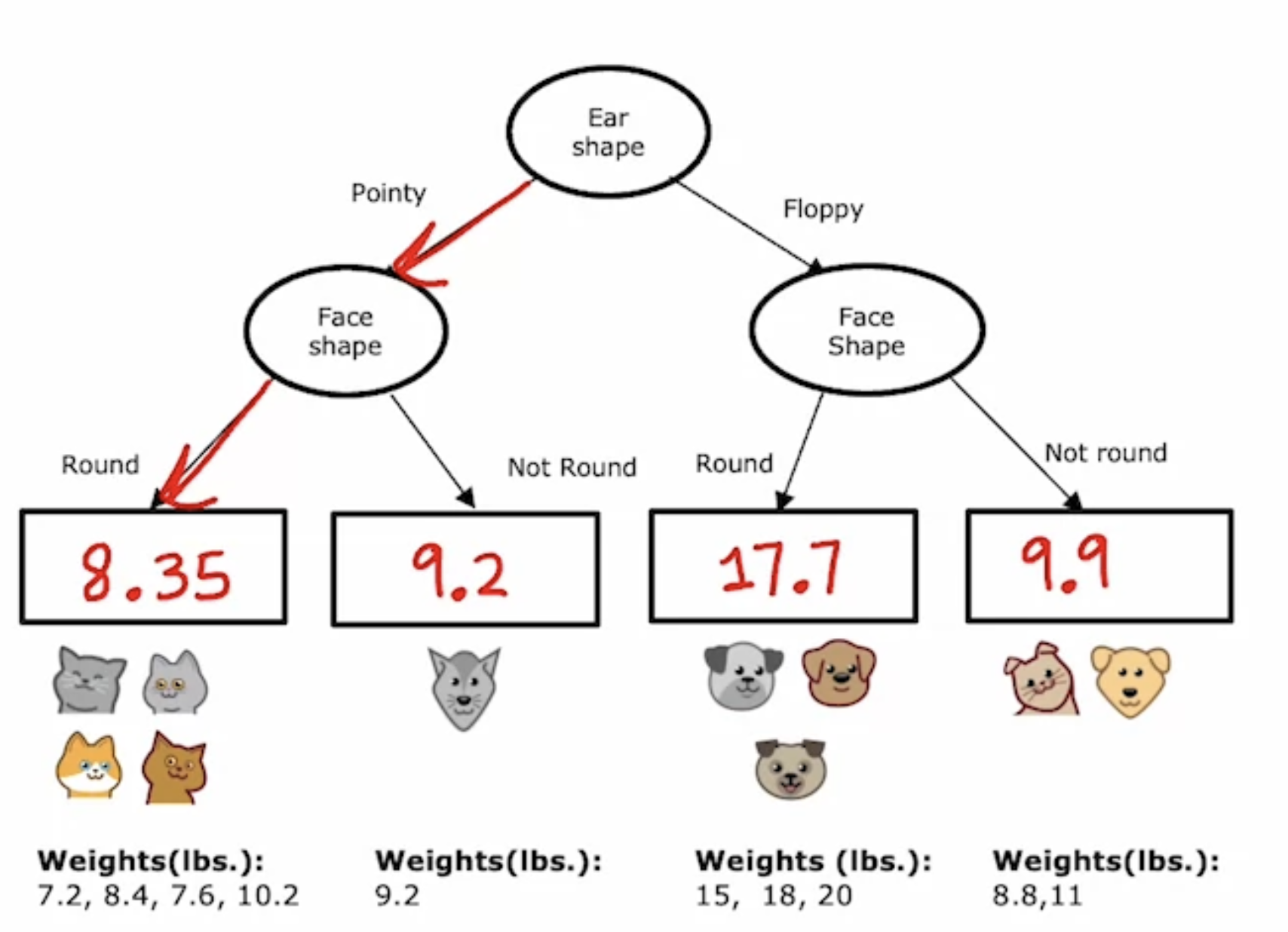
- 해당 class에 해당되는 샘플들의 평균값으로 나온다
- regression 문제에서는 largest reduction in variance를 주는 모델을 고른다
3. Tree ensembles
: collection of multiple trees
: 하나의 tree만 쓰면 작은 변화에도 엄청 sensitive 할 수 있기 때문에, 여러개의 tree를 모아보자
: 여러개의 tree가 각자의 vote를 해서 결과를 낸다
| Sampling with replacement
: 앙상블 트리를 만들기 위해 필수 (100개 샘플이 있으면, 제거없이 계속 100개 안에서 돌리는거)
| Randomizing the feature choice (Random Forest)
: n개의 feature가 있으면, n보다 작은 k개의 random subset을 고르기

| XGBoost (Boosted trees ; eXtreme Gradient Boosting)
빠르고, 쉽고, 여러 대회에서 성공적이었다

| Decision Tree, Tree Ensemble의 활용
- Structured data에 사용 (unstructured data에는 쓰지 말것 ; image, audio, text)
- Fast 빠르다
- Small decision tress may be human interpretable (직관적으로 알고리즘을 알 수 있다)
-Ensemble은 single decision tree보다 연산비용이 비싸지만, 그래도 ensemble이 더 성능이 좋고, 교수님은 웬만하면 XGBoost를 쓰겠다
vs
| Neural Networks의 장점
- 웬만한 모든 데이터 타입에 사용 가능 (structured & unstructured)
- slower than decision tree
- Works with trasnfer learning
- 여러개 model을 만들어야 할때는 연결짓기가 더 쉽다 (gradient descent를 사용해서 다같이 동시에 훈련 가능)



