
무냐의 개발일지
[Coursera ML Specialization] C2 Neural Networks / Week3 (머신러닝 적용하기) 본문
[Coursera ML Specialization] C2 Neural Networks / Week3 (머신러닝 적용하기)
무냐코드 2024. 3. 19. 17:281. 머신러닝 팁 (Advice for applying Machine Learning)
머신러닝을 더 효율적으로 구축하는 방법

* Diagnostic : learning 알고리즘에서 어떤 게 작동하고, 안하는지 확인하고, 성능을 높일 수 있는 가이드를 얻기 위한 작업
| Model Evaluation
모델 성능 확인하는 방법을 배워보자! (아는거)
* Train 데이터와 Test 데이터 나누는 거 (기본)
- 현재 training set에 완벽하게 맞았다고 해도, 새로운 형태의 데이터에는 안 맞을 수 있잖아.
- 데이터를 train, test로 나눠서 을 나눈다
- 훈련에 사용되지 않은 데이터로 테스트하여 맞는 모델을 잘 선택하는 방법 (기본)
1) Regression 문제에서의 활용
: cost function을 최소화하는 파라미터를 찾는다

2) Classification 문제에서의 활용
: 잘못 분류된 부분을 확인한다


* Cross-validation
잘 작동하지 않는 모델을 train, cross validation, test 세트로 데이터를 나눈다
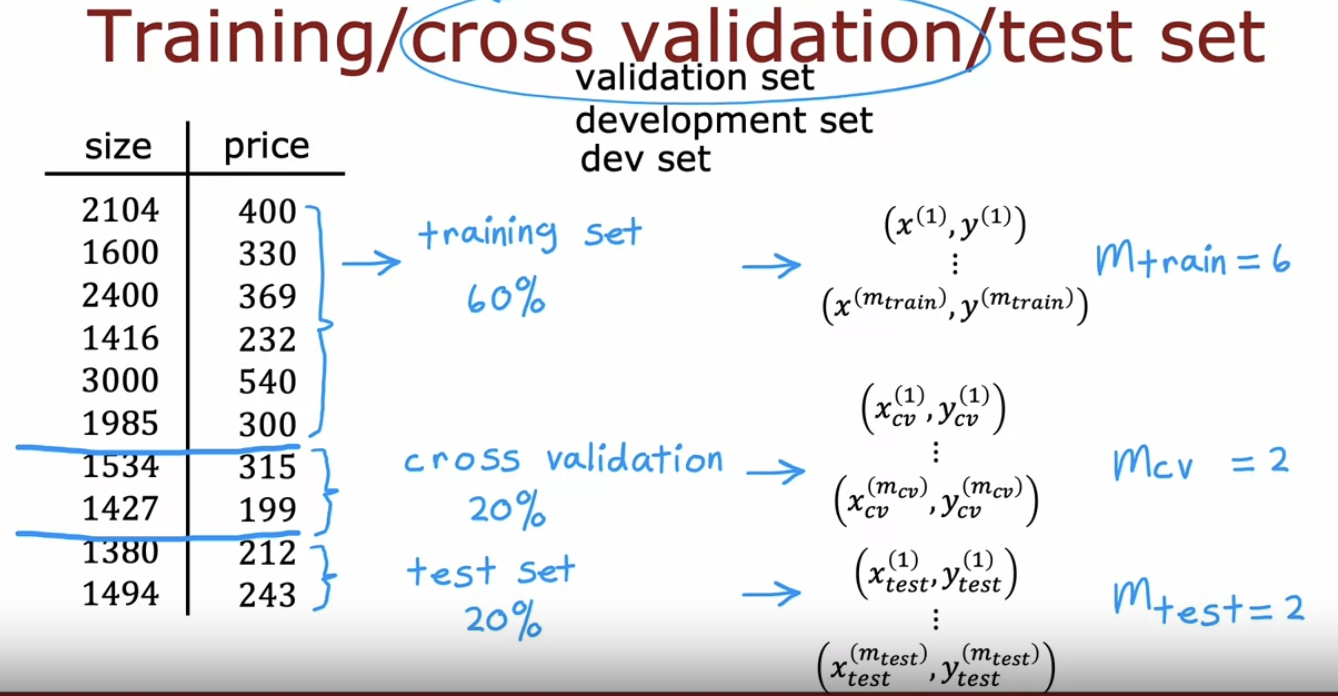
- 훈련 데이터를 또 한 번 나누는거임.
- 모델 훈련 (training set), 모델 검증 (validation set), 최종 평가 (test set)

가장 낮은 cross validation error를 가진 수식을 선택하는 거다 (해당하는 다항식을 선택하는 것)

# Get 60% of the dataset as the training set. Put the remaining 40% in temporary variables: x_ and y_.
x_train, x_, y_train, y_ = train_test_split(x, y, test_size=0.40, random_state=1)
# Split the 40% subset above into two: one half for cross validation and the other for the test set
x_cv, x_test, y_cv, y_test = train_test_split(x_, y_, test_size=0.50, random_state=1)
# Delete temporary variables
del x_, y_- train 60% cv 20% test 20% 으로 나눠지는 결과가 나온다
2. Bias, Variance
| Bias, Variance란?
어차피 처음부터 완벽한 모델은 없음. 그 중에서도 편향, 분산을 보면 다음에 어떤 조치를 취해야할지 잘 알 수 있음

Jtrain에 비해 Jcv가 너무 높은지 아닌지에 따라 판별
- High bias : train set에서조차도 성능이 똥이다
- High variance : cross validation set 에서 성능이 똥망이다
| Regularization 정규화(lambda)가 bias, variance에 어떤 영향을 끼치나


- High bias (under fit) : J train high (train, cv 비슷)
- High variance (over fit) : J train low (cv > train)
- Hight bias & High variance : J train high (cv > train)
Q: 여기서 4차 다항식 모델을 피팅할 때 어떤 적절한 람다값을 찾을 것인가

| Establish Baseline Level of performance
J_cv, J_train 이런 애들이 큰지, 작은지를 확인하기 위해 Baseline 이 필요한거다.
Baseline의 후보군 : 인간 performance, Competing 알고리즘 performance, Guess based on experience
(인간에 비해 잘 하는지를 비교하는게 가장 직관적인 비교겠지?!)

- Baseline <-> Training error 간의 차이가 크면 : High Bias problelm (Training set에서도 성능이 Baseline보다 안좋은거니까)
- Training error <-> CV error 간의 차이가 크면 : High variance problem (CV에서의 성능이 더 안 좋은게 확실하니까, 과적합)
| Learning Curve
training dataset이 얼마나 있는지를 고려한다. training dataset이 클수록 training error가 커진다. 모든 데이터를 다 fit 하기가 어려워지기 때문이다.
- High Bias (train data에서도 구린) 문제에서는, 아무리 training data를 늘린다고 해도, error가 적어지진 않는다. 마지 아래 그림처럼, 모델이 linear인데, 데이터가 아닌 경우랑 같이.

- High Variance
이런 경우에는 train dataset을 늘려주는게 도움이 된다. J_cv는 내려올거고, J_train은 확 올라갈거니까 !!

| 모델을 개선하기 위해 할 6가지

1. 훈련 데이터셋을 늘린다 (High variance 문제를 해결한다)
2. Try Smaller set of features (너무 feature 많으면, 모델이 덜 복잡해질테다. 과적합/ High variance 문제 해결)
3. Get additional features (2번과 반대로, High bias 문제를 해결할거다. 집값 예측에 사이즈만 고려하다가 + 위치 고려)
4. Add polynomial features (추가 feature 추가하는 느낌으로, 곡선을 더 잘 예측하겠지. High bias 문제 해결)
5. Try decreasing lambda (High bias 해결)
6. Increasing lambda (High variance 해결)
* 모델 개발 알고리즘


- regularization을 잘 하면 큰 뉴럴네트워크를 가지는 건 웬만하면 좋다. 하는 방법은 kernal_regularizer = L2(0.01) 이런 식
3. ML Development process
choose architecture -> train model -> diagnostics (bias, variance, error analysis) -> 결정 (뭐를 바꿀건지, 데이터를 더할래, 람다를 변경할래 등등)
| Error Analysis, Adding Data

1. 새로운 데이터를 추가한다.
2. 특정 data type의 데이터만 추가한다
3. Data Augmentation
- 새로운 데이터 얻는 거 말고, Data Augmentation 도 효과적 !!! (기존 데이터를 변형한다. 돌리거나, 확대하거나, 색을 바꾸는 등)
그리고 왜곡시킬 수도 있다.


- 음성데이터의 경우에도, 배경에 noisy background (crowd, car)등을 추가한다던지, bad cellphone connection을 가정해서 추가하는 등을 할 수 있다.
4. Data synthesis
- 다른 색깔, 폰트로 쓴 글자들을 막 합쳐놓는 거 (computer vision task에만 자주 쓰이는 기술이다)


- 데이터를 중심적으로 보는거지.
| Transfer Learning
1. 이미 train된 모델을 가져온다.
2. 그리고 일부만 새로 train시킨다. (단, pre-trained model과 Input type 이 같아야함!!)
| Full cycle of ML project
과제 확인 (뭘 얻고싶은지) -> 데이터 수집 -> 모델 훈련/ 추가 등
MLOps : Machine Learning Operations


- 물론, 머신러닝에 문제가 있기도 하다.
ex) 여성 차별하는 고용시스템, Facial recognition system 어두운 피부색을 범죄자라고 매칭시키는 거, Biased bank loan approvals, Toxic effect of negative stereotypes, Deepfake 기술(남의 얼굴을 가지고 진짜처럼 말하는거), Fake content 뿌리는거 등등

& Develop mitigation plan, and monitor for possible harm (자율주행자동차 같은 거, 사고났을 때 어떻게 할지 등)
| Dealing with Skewed dataset





